ADSP实验室参加ICANN 2019国际会议
撰稿人:甘蕾
2019年9月17日至19日,第二十八届人工神经网络国际会议(28th International Conference on Artificial Neural Networks)在德国慕尼黑隆重召开。北京大学现代信号与数据处理实验室17级硕士生甘蕾、18级硕士生张钰莹两位同学赴德参加了此次会议。
此次大会,ADSP实验室共发表2篇文章,研究内容涉及实验室在人脸表情识别及语音情感识别领域的最新研究进展。

图一会议现场

图2 专家汇报
在人脸表情识别研究中,17级甘蕾同学作为第一作者发表的文章“Discriminative Feature Learning using Two-stage Training Strategy for Facial Expression Recognition” 以poster的形式进行成果展示。文章针对人脸表情识别中的数据不平衡和难分样本问题展开研究,基于代价敏感训练思想提出了一个双阶段训练策略,与第一训练阶段仅采用交叉熵损失函数进行训练相比,双阶段训练策略在第一阶段得到的训练模型基础上进一步采用Focal Loss损失函数进行训练。通过在主流数据库CK+(存在严重数据不平衡问题)和Oulu-CASIA数据库(存在难分样本问题)上的实验结果,证明该训练策略能够缓解数据不平衡和难分样本问题。同时,通过采用多个主干网络进行实验,结果证明,我们提出的该方法不依赖于主干网络,兼具可行性和灵活性。
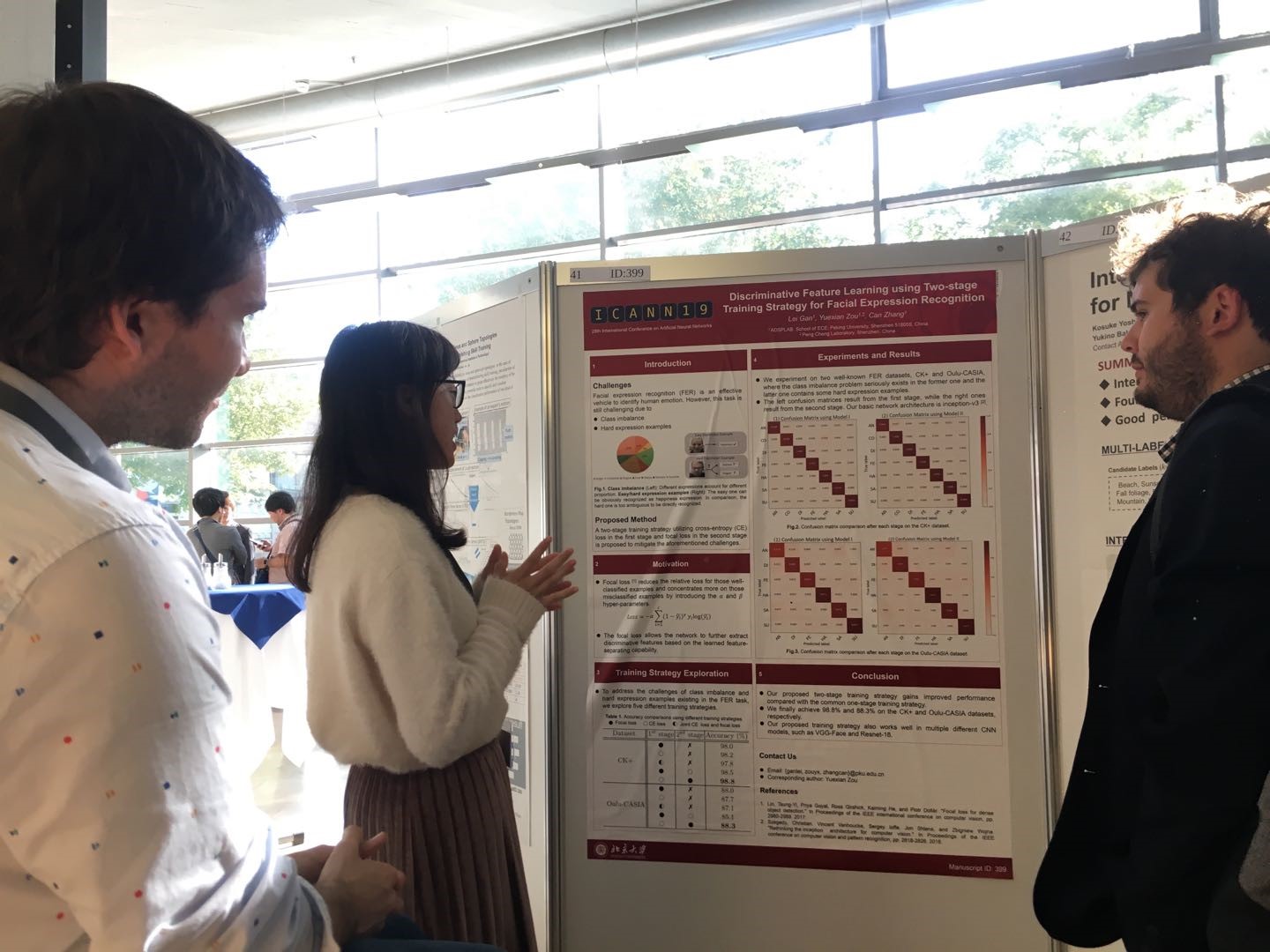 图3 甘蕾同学在会场解答疑问
图3 甘蕾同学在会场解答疑问
在语音情感识别研究中,18级张钰莹同学作为第一作者发表的文章“Discriminative Feature Learning for Speech Emotion Recognition”以poster的形式进行成果展示。该文章针对情感易混淆(难分样本)问题和情感数据类别不平衡问题,提出了基于度量学习和困难样本学习的深度神经网络语音情感识别模型,用于提取更具有区分性的语音情感特征。具体地,模型使用结合Affinity loss 和Focal loss的联合损失函数进行训练。其中,Affinity loss通过最大化深度特征的类间距离和最小化类内距离,学习更具可区分性的情感特征,从而一定程度解决情感易混淆问题;Focal loss通过降低大量简单样本在训练中所占的权重,使得模型在训练过程中更关注于少量困难样本,避免了梯度下降过程中loss被大量简单样本主导,从而缓解情感数据集类别不平衡的问题。该方法在IEMOCAP和EMO-DB两个主流语音情感数据集上进行了实验。与仅使用交叉熵作为损失函数的DNN基线模型相比,该方法的语音情感识别准确率取得了有效提升。
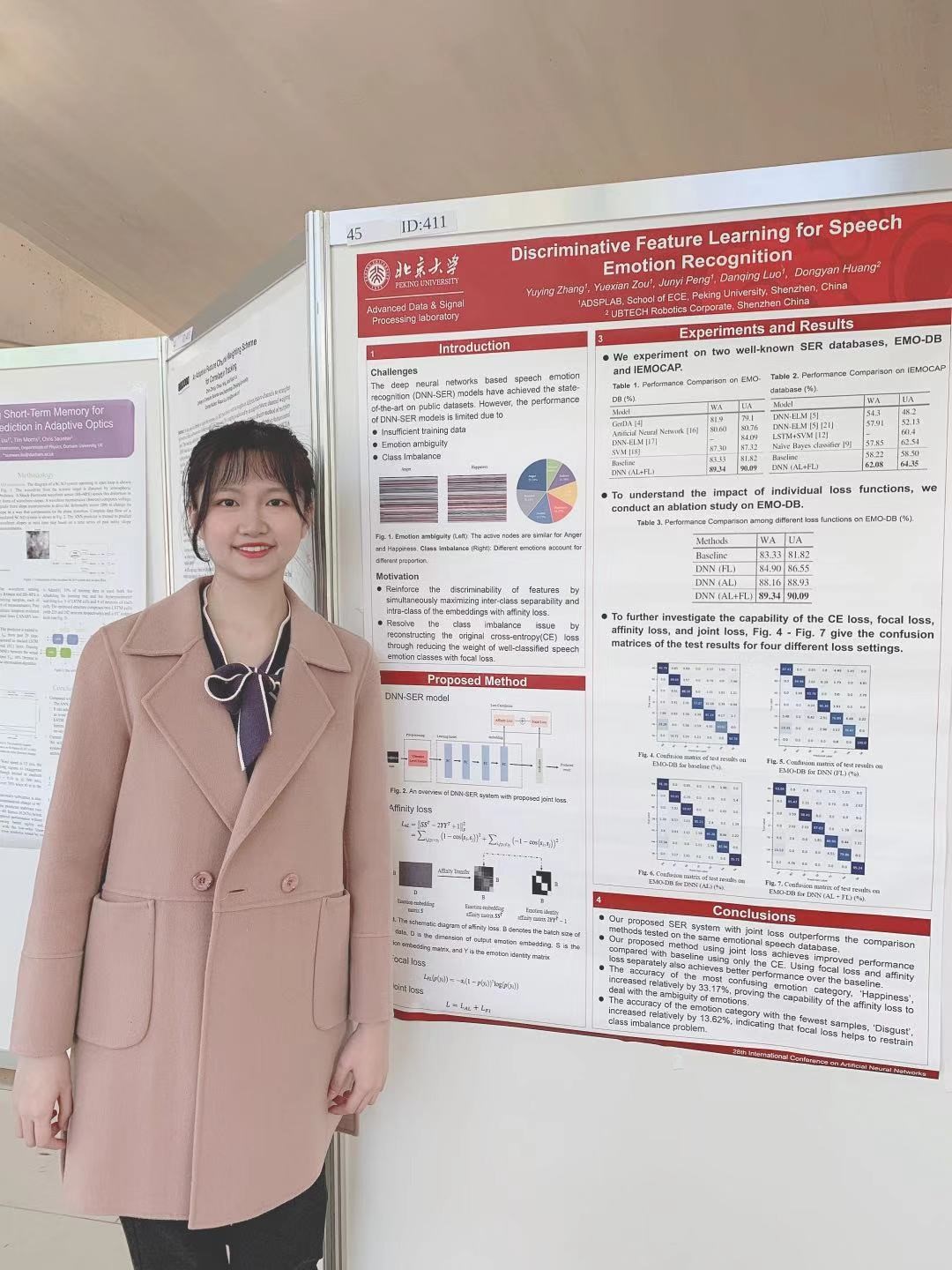 图4 张钰莹同学在会场汇报工作
图4 张钰莹同学在会场汇报工作
除了汇报自己的论文工作之外,甘蕾和张钰莹同学参与了多场专家讲座,并积极地同参会者等进行讨论和交流,收获颇丰。
