ADSP实验室参加APSIPA2019国际会议
 2019年11月18至21日,第十一届亚太地区信号和信息处理协会(Asia-Pacific Signal and Information Processing Association Annual Summit and Conference 2019, APSIPA 2019)在中国(China)兰州(Lanzhou)隆重举行。来自全球学术界和工业界的顶级专家和学者汇聚一堂,共同展示与探讨当代基于深度学习的语音以及其他信号处理行业发展态势及研究成果。
2019年11月18至21日,第十一届亚太地区信号和信息处理协会(Asia-Pacific Signal and Information Processing Association Annual Summit and Conference 2019, APSIPA 2019)在中国(China)兰州(Lanzhou)隆重举行。来自全球学术界和工业界的顶级专家和学者汇聚一堂,共同展示与探讨当代基于深度学习的语音以及其他信号处理行业发展态势及研究成果。

 图1 会议现场
图1 会议现场
此次大会,北京大学现代信号与数据处理实验室(ADSPLAB)共发表3篇文章,研究内容涉及语音分离技术,语音增强技术与说话人识别技术等。
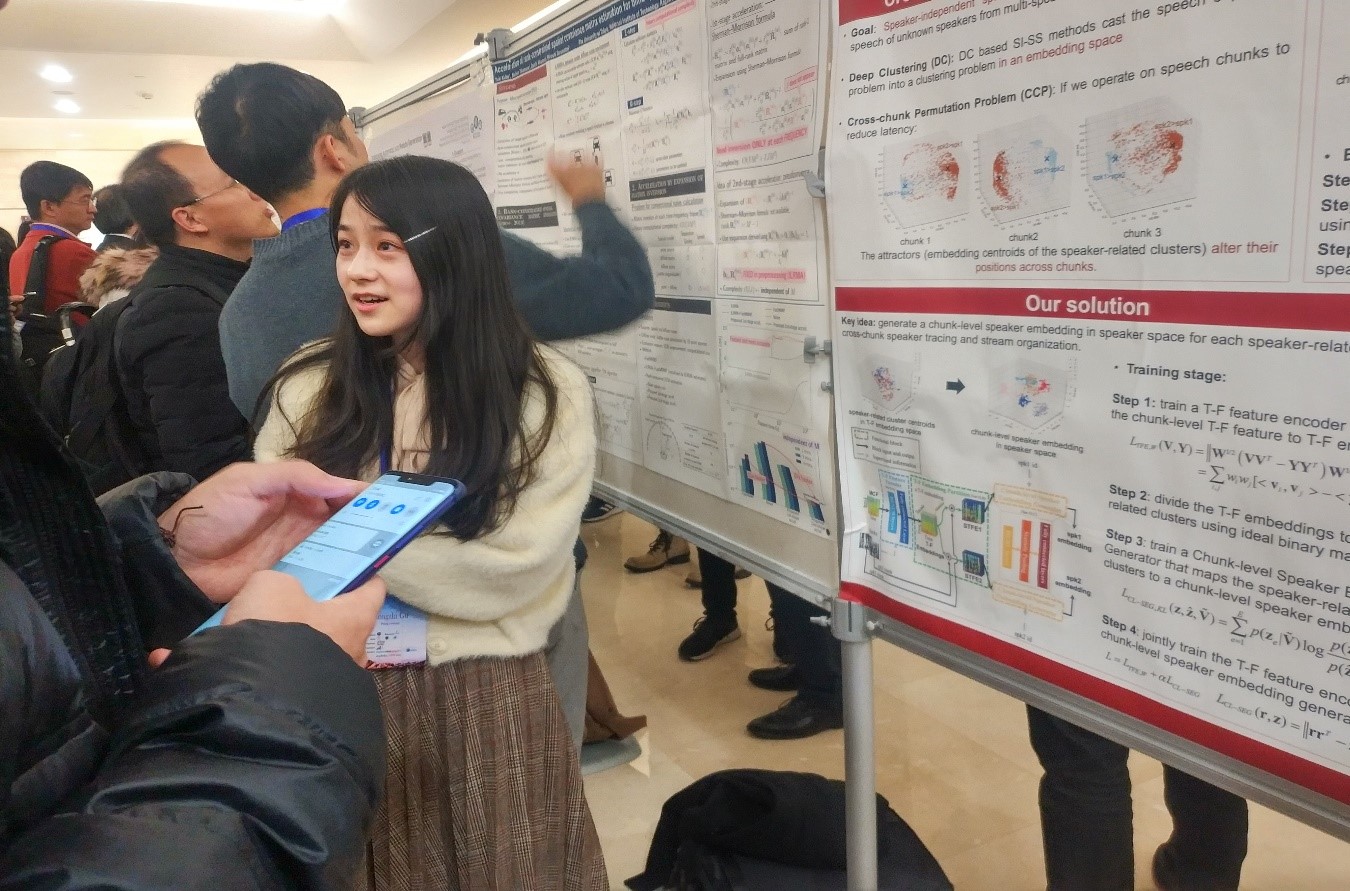 图2 顾容之同学在进行海报展示
图2 顾容之同学在进行海报展示
在语音分离技术研究中,17级博士生顾容之同学作为第一作者发表了文章“Alleviate Cross-chunk Permutation through Chunklevel Speaker Embedding for Blind Speech Separation”,并以poster的形式进行成果展示。本文重点针对目前非特定语音分离技术(SI-SS)中出现的Cross-Chunk Permutation (CCP)问题,在基于深度聚类方法的SI-SS框架下提出生成chunk-level的说话人embedding,从而在模型预测阶段时能够更好地进行聚类和跟踪说话人信息。
 图3 刘钊祎同学在进行口头展示
图3 刘钊祎同学在进行口头展示
在语音增强技术研究中,17级硕士生刘钊祎同学作为第一作者发表了文章“Teacher-Student BLSTM Mask Model for Robust Acoustic Beamforming”,并以oral的形式进行成果展示。本文重点针对目前基于深度学习的多通道语音增强技术中出现data mismatch从而导致模型在真实实录数据下语音识别性能急剧下降的问题,提出基于深度学习中教师-学生框架来进行训练,从而在训练中引入真实实录数据的信息,提升模型最终的语音识别性能。
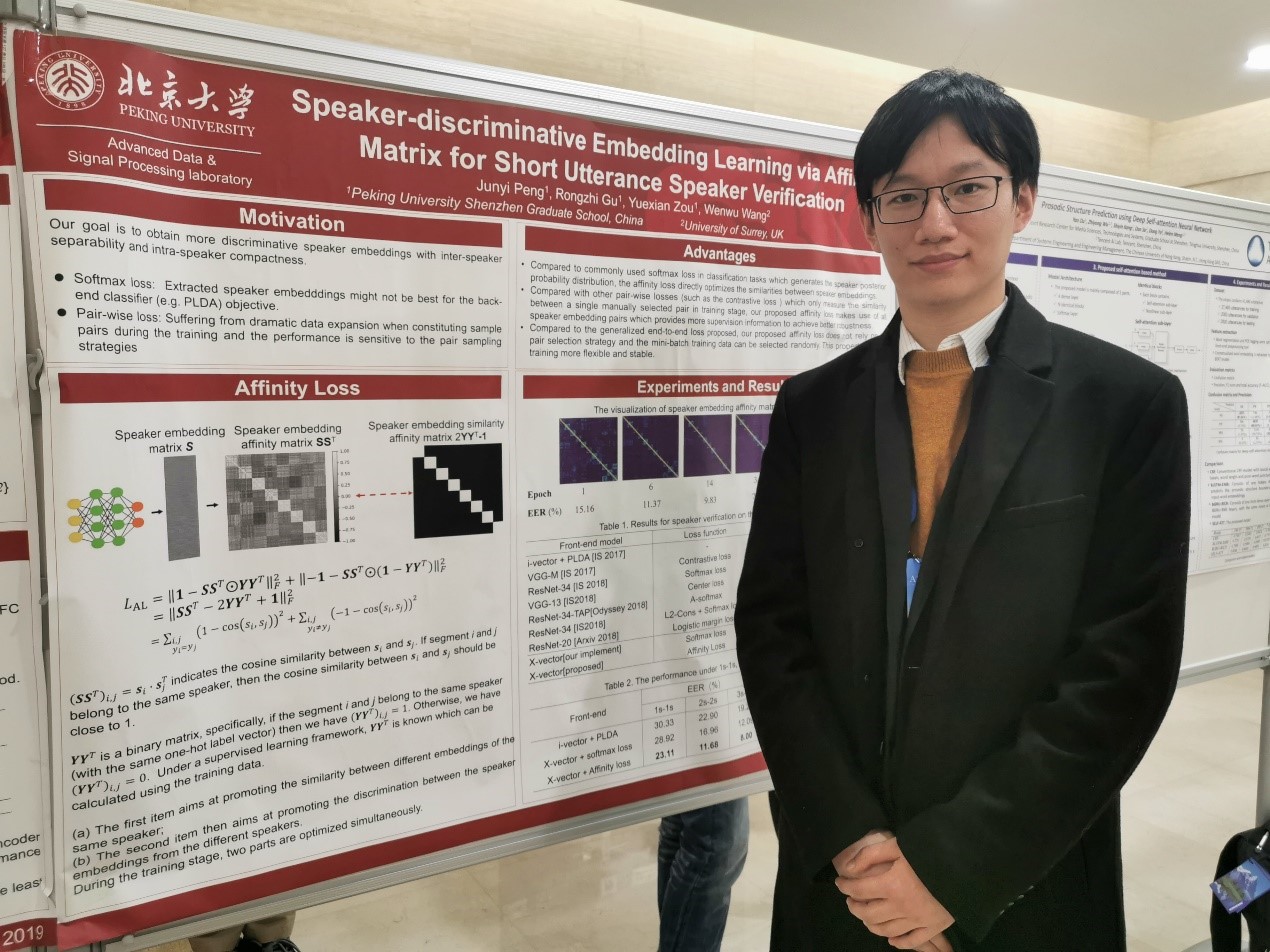 图4 彭俊逸同学在进行poster展示
图4 彭俊逸同学在进行poster展示
在说话人识别技术研究中,17级硕士生彭俊逸同学作为第一作者发表了文章”Speaker-discriminative Embedding Learning via Affinity Matrix for Short Utterance Speaker Verification”,并以poster的形式进行成果展示。本文针对目前i-vector+PLDA方法应用于短语音(SU)说话人识别任务(SV)时性能急剧下降的问题,提出了一种有效的端到端说话人识别系统—Res-BGRU,从而提高了模型在短语音说话人识别任务中的性能。
除了汇报展示论文工作之外,顾容之,刘钊祎和彭俊逸同学参与了多场专家讲座,并积极地同参会者等进行讨论和交流,收获颇丰。

 图5 和参会者与专家们的合影
图5 和参会者与专家们的合影
