ADSP实验室在自然语言处理领域顶级会议COLING上发表学术论文
撰稿人:黄芝琪
近日,邹月娴教授团队在自然语言处理方向顶级会议The 28th International Conference on Computational Linguistics (COLING) 上发表了题为“Federated Learning for Spoken Language Understanding”的学术论文,并以 Oral Paper形式在大会上进行论文的展示。
最近,口语理解(SLU)引起了广泛的研究兴趣,先前的工作提出了各种SLU数据集来促进其发展。但是,大多数现有方法都只关注单个数据集,未能很好地研究如何通过结合各种数据集的优点来提高模型的鲁棒性并获得更好的性能。在本工作中,作者认为,如果将这些SLU数据集一起考虑,则可以共同学习来自不同数据集的不同知识,并且很有可能提高模型在每个数据集上的性能;同时,作者进一步尝试在统一多个数据集的时候防止数据泄漏,这在实际应用场景中非常有必要。为此,作者提出了一个联邦学习框架,该框架可以统一各种类型的数据集以及任务,以学习和融合来自不同数据集和任务的各种类型的知识(即文本表示),而无需共享下游任务数据。融合的文本表示合并了来自不同SLU数据集和任务的信息,因此比单独的单个任务中的原始文本表示功能强大得多。为了给框架提供多粒度文本表示,作者提出了一种新颖的多视图编码器(MV-Encoder,图1)作为联邦学习框架的骨干,其中包括位置层面编码器,局部编码器,全局编码器以及时间序列编码器。
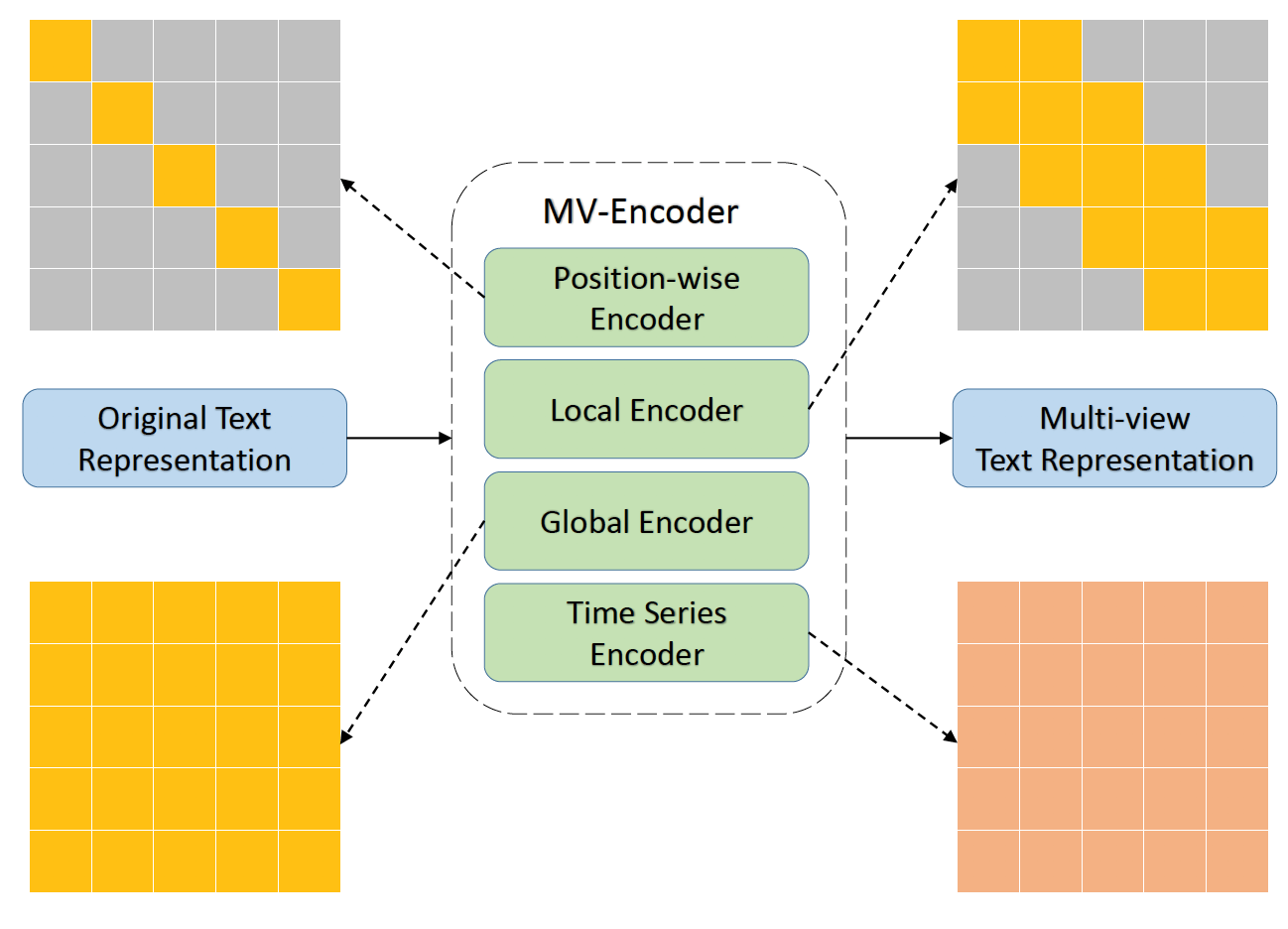
图1. 多视图编码器
本工作在两个SLU基准数据集上的实验,包括两个任务(意图识别和槽位填充)和三种联邦学习设置(水平联邦学习,垂直联邦学习和联邦转移学习),证明了本文提出方法的有效性和普遍性。本文提出的框架可以将意图识别任务的准确性提高1.53 %,还可以在槽位填充任务的F1指标上比强基准性能提高高达5.29 %。此外,通过利用BERT作为附加编码器,联邦学习全模型设置(图2)在SNIPS和ATIS数据集的意图识别和槽位填充任务上建立了目前最好的模型表现。

图2. 联邦学习全模型设置
Computational Linguistics是CCF推荐的B类会议,为自然语言处理领域国际顶级学术会议。2019级硕士生黄芝琪为该论文第一作者,邹月娴教授为通讯作者,该工作得到了Aoto-PKUSZ联合实验室的支持。
