ADSP实验室参加DCASE2021 Challenge并获得优异成绩
近日,在第七届国际权威声学场景和事件检测及分类竞赛 IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE2021 Challenge) 中,ADSP实验室主任邹月娴与学生杨东超、叶忠杰和王赫麟参加了小样本鸟类声音事件检测 (Few-shot Bioacoustic Event Detection, Task 5) 任务和自动音频字幕(Automated Audio Captioning, Task 6)任务竞赛,并从百余支来自全球顶尖学术界和工业界的声学研究队伍中脱颖而出,分别取得了国际第1名、第4名的成绩。
DCASE 比赛是由伦敦玛丽女王大学(Queen Mary University of London)在2013年首次发起的声学场景识别挑战,后续由坦佩雷理工大学(Tampere University of Technology)持续发起,引起了国内外众多尖端声学研究界的广泛关注。本次DCASE 2020比赛共设置六个任务,包括声学场景识别、异常机器声音的非监督识别、声学事件定位与检测、声学事件分离、鸟类声音时间检测和自动音频字幕,吸引了包括亚马逊、英特尔、高通骁龙、日本NTT等国际公司和清华大学、新加坡南洋理工大学、上海交通大学等顶级高校参赛。 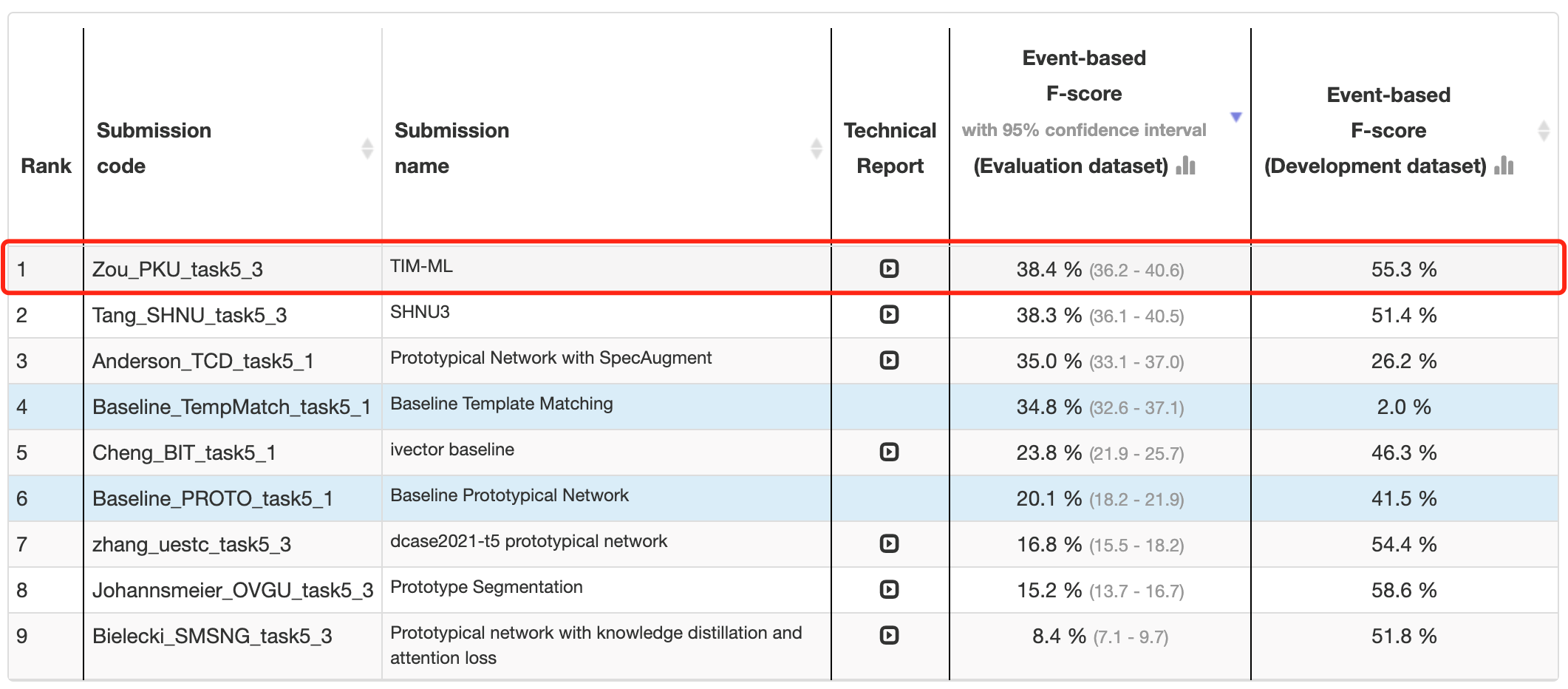

小样本学习是一种非常有前途的声音事件检测范式。它也非常适合生物声学用户的需求,其中越来越大的声学数据集通常需要针对已识别类别(例如物种或呼叫类型)的事件进行标记,即使该类别在其他数据集是未知的或没有已知标签。在DCASE Task 5的任务中,侧重于动物(哺乳动物和鸟类)发声的小样本学习设置中的声音事件检测。 参与者将需要创建一种方法,该方法可以从哺乳动物或鸟类的五个示例发声中提取信息,并在现场录音中检测和分类声音。ADSP团队成员分析了经典的原型网络表现不佳的原因,并使用转导推理的方法进行小样本学习。 所提出的方法结合基于支持集的监督损失,最大化查询特征与其标签预测之间的互信息。此外,ADSP团队提出了一个相互学习的框架,使特征提取器和分类器相互帮助。最终在验证集上达到了55.26%的F-score值。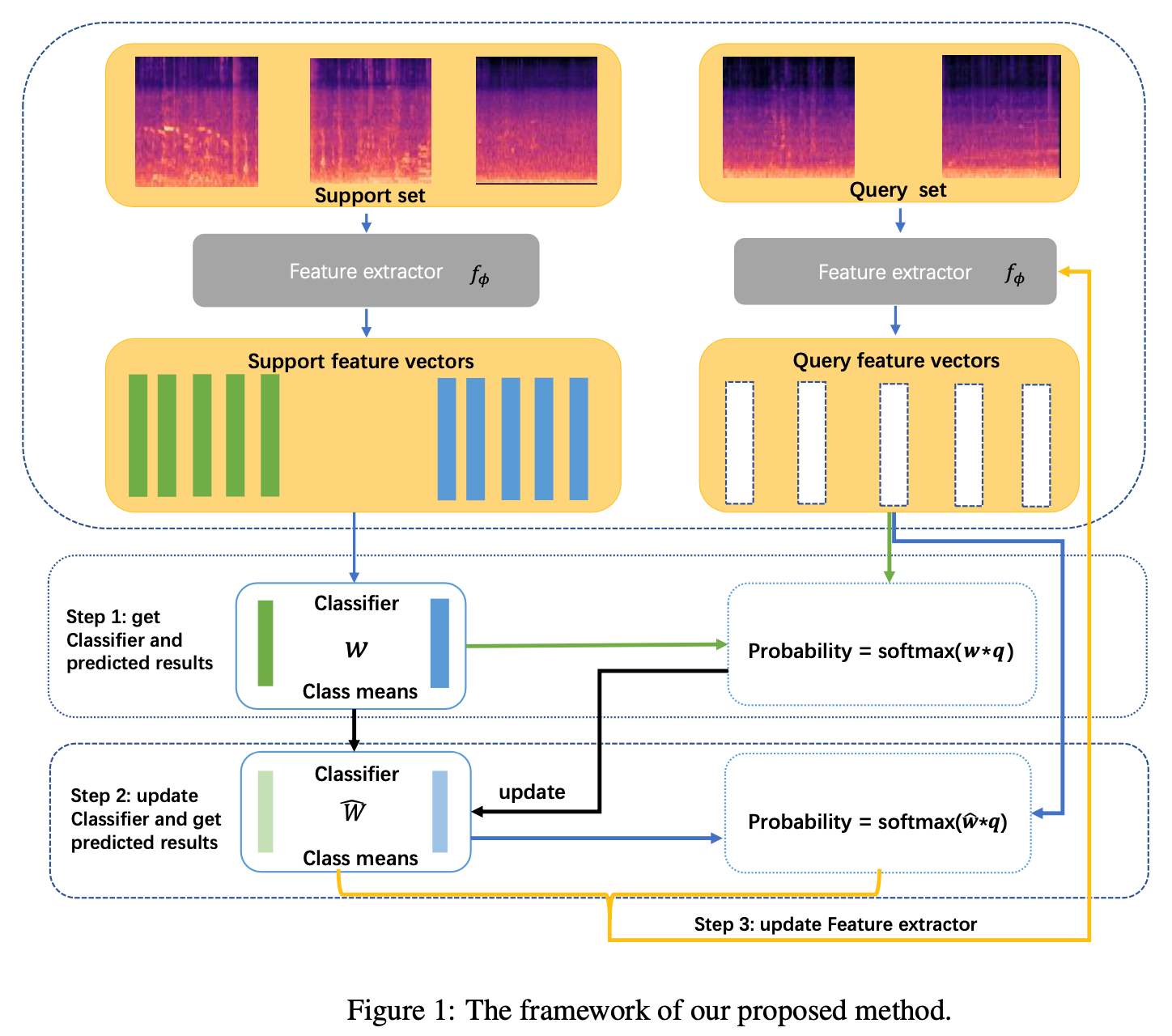
自动音频字幕是使用文本进行一段音频内容描述的任务。这是一个模态间翻译任务(不是语音到文本),其中系统接受音频信号作为输入并输出该信号的文本描述。 自动音频字幕方法可以对概念(例如“低沉的声音”)、物体和环境的物理特性(例如“大汽车的声音”、“人们在小而空的房间里说话”)和高级知识(例如“时钟响三声”)进行建模。这种建模可用于各种应用,从自动内容描述到智能和面向内容的机器对机器交互。在DCASE Task 6的任务中,为了利用更多的声学和文本信息,ADSP团队提出了一种新型序列到序列的模型,具有关键字预训练的编码器和多模态注意力解码器。对于编码器,我们在 AudioSet 数据集上使用预训练的分类模型,并使用名词和动词的关键字作为标签对其进行微调。此外,提出了一个多模态注意力模块来整合解码器中的声学和文本信息。我们的单一模型在验证集上达到了 0.279的SPIDEr分数。除此之外,通过强化学习优化CIDEr-D指标的最佳集成模型达到了0.291的SPIDEr分数。

