邹月娴课题组一项工作被国际旗舰期刊IEEE TPAMI接收
近日,邹月娴课题组以北京大学深圳研究生院为第一完成单位的1篇论文在国际旗舰期刊IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI, 影响因子23.6)上发表,论文题目为《ZeroNLG: Aligning and Autoencoding Domains for Zero-Shot Multimodal and Multilingual Natural Language Generation》,博士生杨邦为共一作者。
论文内容简介:自然语言生成(Natural Language Generation, NLG)接受图像、视频或文本形式的输入数据,并生成相应的自然语言文本作为输出。现有的NLG方法主要采用有监督学习范式,严重依赖于数据-文本配对数据。然而,许多有针对性的场景和非英语语言通常无法获得充足的标记数据,而收集和标注用于训练的数据-文本对是既昂贵又耗时的。为了减轻对下游任务标记数据的依赖,本文提出了一个直观有效的零样本学习框架ZeroNLG,它可以在一个统一的框架内处理多个NLG任务,包括图像到文本(图像描述)、视频到文本(视频描述)和文本到文本(神经机器翻译)。
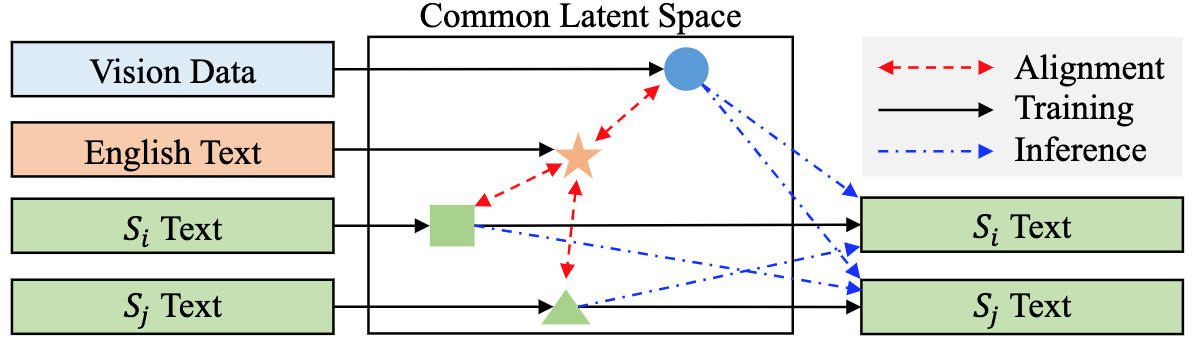
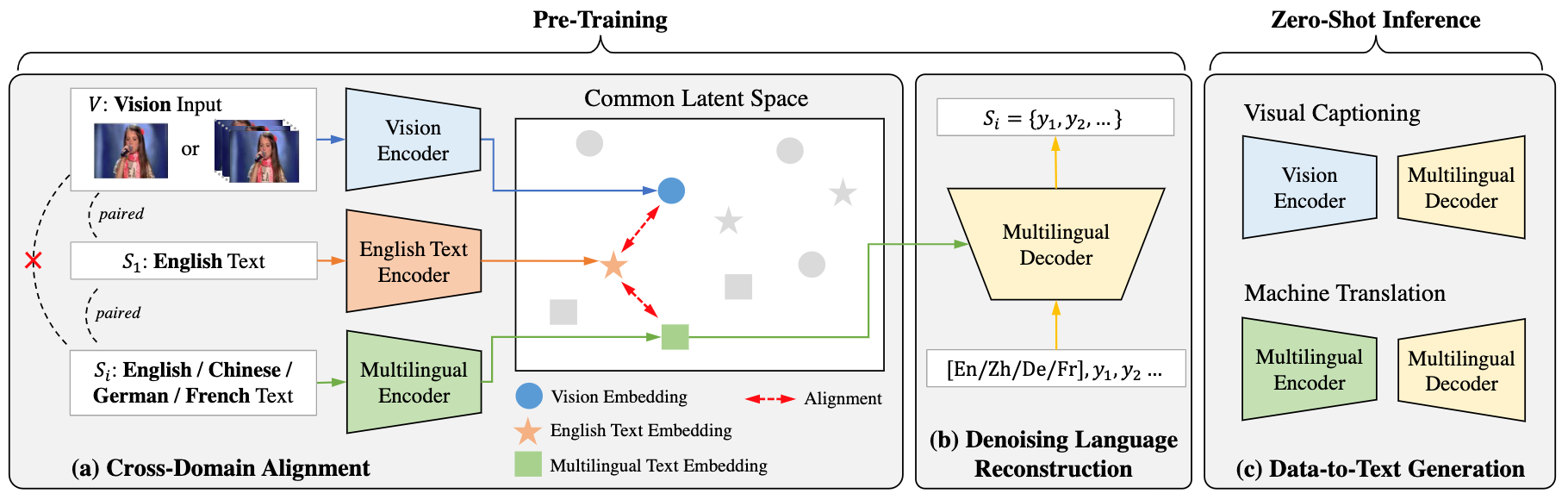
如上所示,在训练期间,ZeroNLG(i)将跨模态和语言的不同域投影到共享的隐空间中的相应坐标;(ii)以英文作为“锚点”(anchor),利用现有的、丰富的英文和其他模态/语言的配对数据,实现不同域数据的相互对齐;以及(iii)建立一个无监督的多语言自动编码器,以通过在共享隐空间中给定坐标的情况下重构输入文本来学习生成文本。因此,在推理过程中,基于数据到文本的流水线,ZeroNLG可以在给定输入数据在共享隐空间中的坐标的情况下生成不同语言的目标句子。在这个统一的框架内,给定视觉(图像或视频)数据作为输入,ZeroNLG可以实现零样本视觉描述;给定文本句子作为输入,ZeroNLG可以执行零样本机器翻译。下图展示了ZeroNLG框架的具体实现。
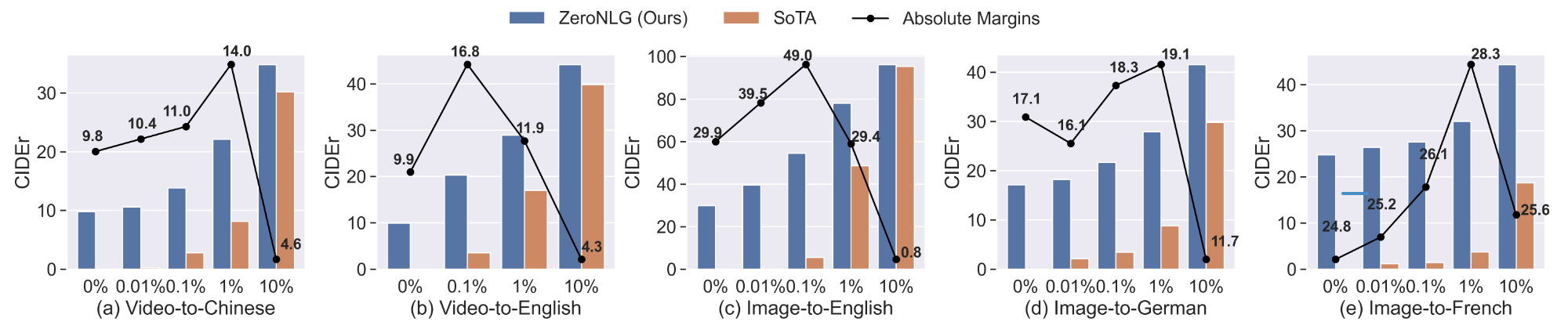
本文在12个NLG任务上进行了广泛实验,结果表明在不使用任何下游数据-文本配对数据进行训练的情况下,ZeroNLG取得了先进性能并能够生成高质量输出。在半监督学习情形下,如下图折线所示,在使用不同比例标注数据用于训练时,ZeroNLG相比先进方法有着大幅的性能提升。这表明了所提框架对减轻数据-文本配对数据依赖的有效性。
论文链接:https://ieeexplore.ieee.org/document/10453989
项目链接:https://github.com/yangbang18/ZeroNLG
