ADSP实验室在人工智能顶级会议IJCAI2020上发表学术论文
撰稿人:杨东明
我实验室视频小组题为“A Graph-based Interactive Reasoning for Human-Object Interaction Detection”的学术论文被人工智能顶会IJCAI2020接收。
人-物交互(Human-Object Interaction, HOI)检测是机器视觉理解中的一项重要研究内容,目标是检测视觉场景中人与物体之间存在的具有语义的交互行为。其以图像或视频帧作为输入,将在输入数据中输出检测到的交互行为并使用边界框(Bounding Box,Bbox)对交互主体进行定位。相比传统的动作检测、识别任务,HOI 检测任务需要在复杂的多人、多物体视觉场景中检测出每一对<人、物>二元组之间可能存在的多种不同的交互行为。
最近的HOI检测方法主要依赖于附加注释(例如,提取人的姿态)来提高检测性能,忽略了卷积操作之外目标实例之间的交互推理。我们提出了一种新颖的基于图的交互式推理模型,称为交互式图(简称i n-Graph)来推断HOI,有效地挖掘了视觉目标之间的交互式语义。
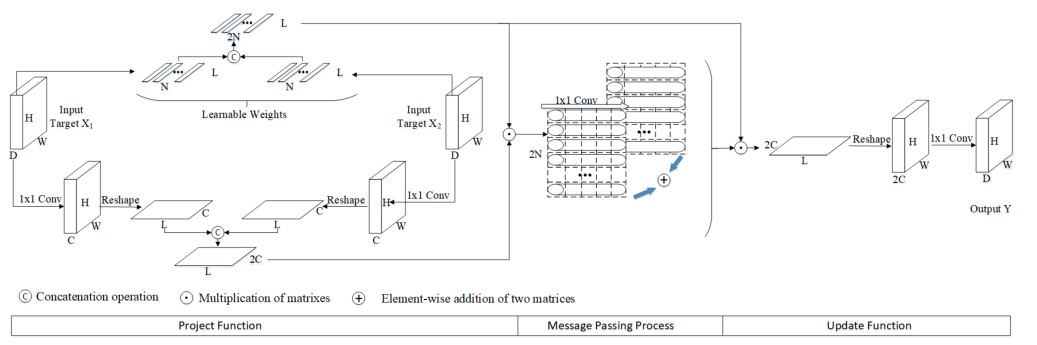
图:in-Graph模型的详细设计
in-Graph模型包含三个核心过程,即,映射函数(Project Function),消息传递过程(Message Passing Process)和更新函数(Update Function)。在这里,映射函数会生成一个统一的图空间,以使两个相关的视觉目标可以相互融合和互操作。消息传递过程通过在所生成图的节点之间传播消息来集成交互式语义。最后,更新函数将推理的节点转换回卷积空间,从而提供针对HOI建模的交互式语义特征。

图:in-GraphNet示意图
基于提出的In-Graph模型,文章提出一个称为in-GraphNet的框架,隐式地解析场景范围(scene-wide)和实例范围(instance-wide)的交互式语义,而不是分别地对每个视觉目标进行特征提取。具体来讲,所提出的in-GraphNet是组装两级in-Graph模型(即,scene-wide In-Graph和scene-wide In-Graph)的多流网络。通过结合多层级的交互式语义来做出最终的HOI预测。
通过以上设计,所提出的框架可以端到端训练,并且没有使用人体姿势等辅助标签。大量实验表明,文章提出的框架在V-COCO和HICO-DET基准上均优于现有的HOI检测方法,并且相对提高了基线约9.4%和15%,从而验证了其检测HOI的有效性。
IJCAI是CCF推荐的A类会议,视频小组内杨东明博士生为该论文的第一作者,邹月娴教授为通讯作者。
